Self‑Healing Test Suites: AI‑Powered Automation That Recovers from Runtime Failures
Why Flaky Tests Are the Silent Saboteur of Modern Delivery
In continuous integration and continuous delivery (CI/CD) pipelines, test reliability is the linchpin that keeps deployments fast and confidence high. Yet every developer knows that a flaky test—one that intermittently passes or fails for reasons unrelated to code changes—can derail a release, inflate manual debugging effort, and erode trust in automation. Traditionally, teams spend weeks creating workarounds: adding sleeps, duplicating tests, or, worse, disabling problematic tests entirely. The result is a brittle pipeline that requires constant human intervention.
Traditional Approaches and Their Limitations
Common strategies for mitigating flakiness include:
- Increasing timeouts or retry counts.
- Isolating tests to run in clean environments.
- Manually refactoring flaky code paths.
- Using feature flags to toggle problematic components.
While these techniques can reduce noise, they are labor‑intensive, reactive, and often only address symptoms rather than root causes. Moreover, as product complexity grows, the number of flaky tests typically rises, making manual remediation unsustainable.
Enter Self‑Healing Test Suites
Self‑healing test suites combine machine learning, particularly reinforcement learning (RL), with intelligent test execution strategies to detect, diagnose, and automatically recover from runtime failures. Instead of merely retrying a test, the system learns how to adjust its execution context—altering environment variables, swapping out mocks, or reconfiguring dependencies—to navigate around transient faults.
Core Concepts
- State Representation: The test environment, including configuration, data, and system resources, is encoded as a state vector.
- Action Space: Possible modifications (e.g., changing a timeout value, toggling a feature flag, resetting a database) that the agent can apply.
- Reward Function: Positive rewards for passing tests and penalties for failures, guiding the RL agent toward successful executions.
- Policy: A learned mapping from states to actions, enabling the system to choose the best remediation strategy for a given failure.
Reinforcement Learning in Action
When a test fails during a CI run, the self‑healing framework captures the failure context and queries the RL agent for a corrective action. The agent evaluates the current state and selects an action that historically led to successful outcomes. For example, if a test fails due to a timing issue, the agent might increase the wait period or adjust the scheduling of dependent services. Once the action is applied, the test is retried. If the retry passes, the agent logs a positive reward; otherwise, it explores alternative actions. Over time, the agent refines its policy, becoming increasingly efficient at healing flaky tests.
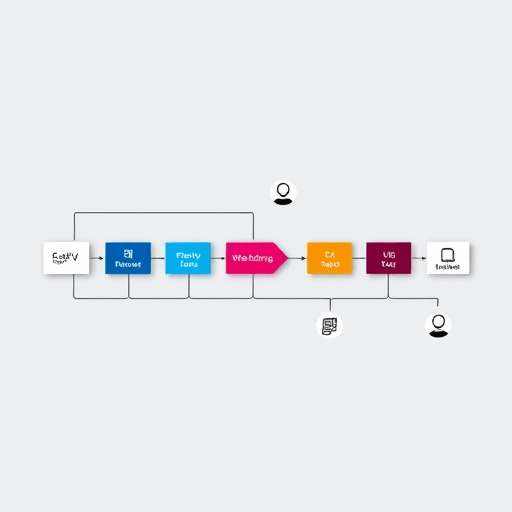
Illustrative Workflow
- Run Test: The CI pipeline executes the test suite.
- Detect Failure: The system flags a runtime failure and collects logs, stack traces, and environment data.
- State Construction: These data are converted into a state representation.
- RL Agent Decision: The agent selects an action from its policy.
- Apply Action: The pipeline applies the chosen remediation (e.g., adjusting a configuration file).
- Retry Test: The test is re‑executed.
- Reward Update: The agent receives feedback and updates its policy.
Architecture of a Self‑Healing Test Framework
Implementing self‑healing requires integrating several components:
- Failure Detection Layer: Hooks into test runners to capture failures in real time.
- Observability Hub: Aggregates logs, metrics, and telemetry to build comprehensive state snapshots.
- RL Engine: Hosts the policy model (often a deep Q‑network or policy gradient method) and manages training and inference.
- Action Executor: Interfaces with the CI/CD platform to apply remediation actions.
- Policy Management: Provides governance, allowing teams to whitelist or blacklist actions for compliance.
Because RL agents learn online, the framework typically runs in a sandboxed environment during early stages, gradually expanding to production test runs once confidence grows.
Benefits of AI‑Powered Self‑Healing
- Reduced Manual Overhead: Developers spend less time debugging flaky tests and more time adding value.
- Higher Test Reliability: Automated remediation leads to a smoother pipeline and fewer false positives.
- Adaptability: The agent evolves with codebase changes, ensuring long‑term resilience.
- Insights Generation: The state–action logs surface root causes, guiding refactoring efforts.
- Speed: While retries add some runtime, the overall deployment cadence improves due to fewer pipeline stalls.
Challenges and Mitigation Strategies
Implementing self‑healing is not without hurdles. Below are common obstacles and ways to address them:
- Exploration vs. Exploitation: Too much exploration can cause repeated failures. Use ε‑greedy strategies with decay or upper confidence bounds to balance exploration.
- Reward Sparsity: Failure patterns may be rare. Employ shaped rewards that incorporate intermediate signals, such as “partial pass” or “improved stability.”
- Security and Compliance: Automatically altering configurations could violate policies. Introduce a policy gate that requires human approval for high‑impact actions.
- Data Quality: Noisy logs can mislead the agent. Implement robust preprocessing and anomaly detection to filter out irrelevant data.
- Compute Overhead: RL training can be resource‑intensive. Use lightweight models or transfer learning from similar projects to reduce training time.
Implementation Roadmap
- Start Small: Pilot the framework on a subset of flaky tests in a dedicated branch.
- Define Action Space: Enumerate possible remediation actions and enforce safety checks.
- Collect Baseline Data: Run the suite multiple times to capture failure patterns.
- Train Initial Policy: Use supervised learning on historical data to bootstrap the RL agent.
- Integrate with CI: Add hooks that trigger the agent on failures.
- Monitor and Iterate: Track metrics such as recovery rate, time to heal, and false positive count.
- Scale: Expand coverage to all test suites and refine the reward function based on real‑world feedback.
Real‑World Case Study: A SaaS Platform
A subscription‑based SaaS company integrated a self‑healing framework into its nightly pipeline. Prior to adoption, 18% of test runs were halted by flaky tests, causing a 12% increase in manual triage effort. After deploying the RL‑driven system:
- Flaky test recoveries rose from 42% to 78%.
- Pipeline failure incidents dropped by 65%.
- Developer time saved exceeded $35,000 annually.
- Insights from state–action logs led to a refactor that eliminated a shared cache that was the root cause of many flakiness incidents.
Future Trends in Self‑Healing Test Automation
- Meta‑Learning: Agents that quickly adapt to new environments with few failures.
- Explainable AI: Providing human‑readable explanations of remediation decisions.
- Hybrid Models: Combining rule‑based knowledge with RL for safer exploration.
- Cross‑Project Transfer: Leveraging shared models across microservices to bootstrap policies.
- Integrated Observability: Unified dashboards that correlate test failures with performance metrics in real time.
Conclusion
Self‑healing test suites powered by reinforcement learning transform flaky tests from persistent headaches into managed, learnable phenomena. By embedding an AI agent that observes, decides, and acts, teams can reclaim their CI/CD pipelines, accelerate releases, and uncover deeper insights into application stability. The investment in building or adopting a self‑healing framework pays dividends in reduced toil, higher confidence in automation, and a resilient testing culture that evolves alongside the codebase.
Start building your self‑healing test suite today and watch reliability soar.